Training: Checkpoints, Logging, and Callbacks¶
In this notebook we will cover a quickstart training of the Split Delivery Vehicle Routing Problem (SDVRP), with some additional comments along the way. The SDVRP is a variant of the VRP where a vehicle can deliver a part of the demand of a customer and return later to deliver the rest of the demand.
![]()
Installation¶
Uncomment the following line to install the package from PyPI. Remember to choose a GPU runtime for faster training!
Note: You may need to restart the runtime in Colab after this
[1]:
# !pip install rl4co
## NOTE: to install latest version from Github (may be unstable) install from source instead:
# !pip install git+https://github.com/ai4co/rl4co.git
Imports¶
[2]:
import torch
from lightning.pytorch.callbacks import ModelCheckpoint, RichModelSummary
from rl4co.envs import SDVRPEnv
from rl4co.models.zoo import AttentionModel
from rl4co.utils.trainer import RL4COTrainer
/home/cbhua/.local/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Main Setup¶
Environment, Model and LitModule¶
[3]:
# RL4CO env based on TorchRL
env = SDVRPEnv(num_loc=20)
# Model: default is AM with REINFORCE and greedy rollout baseline
model = AttentionModel(env,
baseline='rollout',
train_data_size=100_000, # really small size for demo
val_data_size=10_000)
/home/cbhua/miniconda3/envs/rl4co-user/lib/python3.10/site-packages/lightning/pytorch/utilities/parsing.py:198: Attribute 'env' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['env'])`.
/home/cbhua/miniconda3/envs/rl4co-user/lib/python3.10/site-packages/lightning/pytorch/utilities/parsing.py:198: Attribute 'policy' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['policy'])`.
Test greedy rollout with untrained model and plot¶
[4]:
# Greedy rollouts over untrained model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
td_init = env.reset(batch_size=[3]).to(device)
model = model.to(device)
out = model(td_init.clone(), phase="test", decode_type="greedy", return_actions=True)
# Plotting
print(f"Tour lengths: {[f'{-r.item():.2f}' for r in out['reward']]}")
for td, actions in zip(td_init, out['actions'].cpu()):
env.render(td, actions)
Tour lengths: ['19.39', '19.80', '20.77']
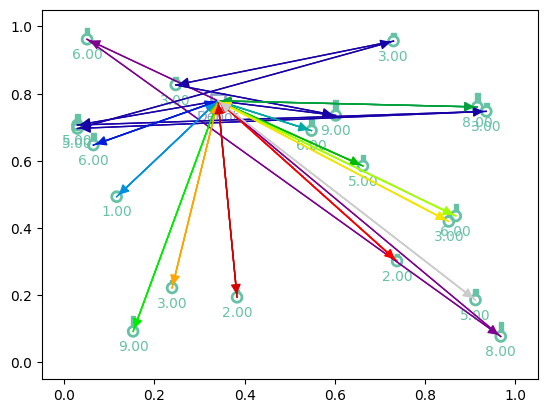
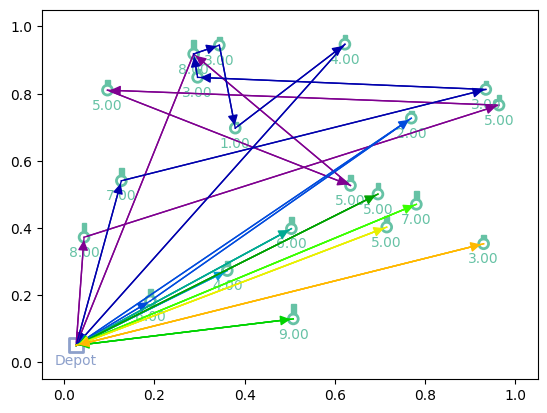
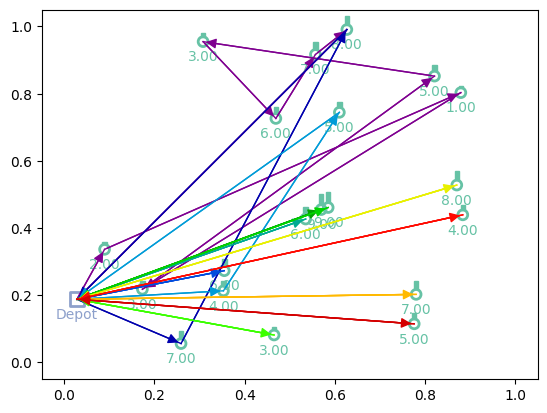
Training¶
Callbacks¶
Here we set up a checkpoint callback to save the best model and another callback for demonstration (nice progress bar). You may check other callbacks here
[5]:
# Checkpointing callback: save models when validation reward improves
checkpoint_callback = ModelCheckpoint( dirpath="checkpoints", # save to checkpoints/
filename="epoch_{epoch:03d}", # save as epoch_XXX.ckpt
save_top_k=1, # save only the best model
save_last=True, # save the last model
monitor="val/reward", # monitor validation reward
mode="max") # maximize validation reward
# Print model summary
rich_model_summary = RichModelSummary(max_depth=3)
# Callbacks list
callbacks = [checkpoint_callback, rich_model_summary]
Logging¶
Here we will use Wandb. You may comment below lines if you don’t want to use it. You may check other loggers here
We make sure we’re logged into W&B so that our experiments can be associated with our account. You may comment the below line if you don’t want to use it.
[6]:
# import wandb
# wandb.login()
[7]:
## Comment following two lines if you don't want logging
from lightning.pytorch.loggers import WandbLogger
logger = WandbLogger(project="rl4co", name="sdvrp-am")
## Keep below if you don't want logging
# logger = None
Trainer¶
The RL4CO trainer is a wrapper around PyTorch Lightning’s Trainer class which adds some functionality and more efficient defaults
The Trainer handles the logging, checkpointing and more for you.
[8]:
from rl4co.utils.trainer import RL4COTrainer
trainer = RL4COTrainer(
max_epochs=2,
accelerator="gpu",
devices=1,
logger=logger,
callbacks=callbacks,
)
Using 16bit Automatic Mixed Precision (AMP)
Trainer already configured with model summary callbacks: [<class 'lightning.pytorch.callbacks.rich_model_summary.RichModelSummary'>]. Skipping setting a default `ModelSummary` callback.
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Fit the model¶
[9]:
trainer.fit(model)
Failed to detect the name of this notebook, you can set it manually with the WANDB_NOTEBOOK_NAME environment variable to enable code saving.
wandb: Currently logged in as: cbhua. Use `wandb login --relogin` to force relogin
./wandb/run-20231201_170900-eznnqzkv
val_file not set. Generating dataset instead
test_file not set. Generating dataset instead
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
┏━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ ┡━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━┩ │ 0 │ env │ SDVRPEnv │ 0 │ │ 1 │ policy │ AttentionModelPolicy │ 694 K │ │ 2 │ policy.encoder │ GraphAttentionEncoder │ 595 K │ │ 3 │ policy.encoder.init_embedding │ VRPInitEmbedding │ 896 │ │ 4 │ policy.encoder.net │ GraphAttentionNetwork │ 594 K │ │ 5 │ policy.decoder │ AutoregressiveDecoder │ 98.8 K │ │ 6 │ policy.decoder.context_embedding │ VRPContext │ 16.5 K │ │ 7 │ policy.decoder.dynamic_embedding │ SDVRPDynamicEmbedding │ 384 │ │ 8 │ policy.decoder.project_node_embeddings │ Linear │ 49.2 K │ │ 9 │ policy.decoder.project_fixed_context │ Linear │ 16.4 K │ │ 10 │ policy.decoder.logit_attention │ LogitAttention │ 16.4 K │ │ 11 │ baseline │ WarmupBaseline │ 694 K │ │ 12 │ baseline.baseline │ RolloutBaseline │ 694 K │ │ 13 │ baseline.baseline.model │ AttentionModelPolicy │ 694 K │ │ 14 │ baseline.warmup_baseline │ ExponentialBaseline │ 0 │ └────┴────────────────────────────────────────┴───────────────────────┴────────┘
Trainable params: 1.4 M Non-trainable params: 0 Total params: 1.4 M Total estimated model params size (MB): 5
/home/cbhua/miniconda3/envs/rl4co-user/lib/python3.10/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:441: The 'val_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=31` in the `DataLoader` to improve performance.
/home/cbhua/miniconda3/envs/rl4co-user/lib/python3.10/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:441: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=31` in the `DataLoader` to improve performance.
Epoch 1: 100%|██████████| 196/196 [00:09<00:00, 21.74it/s, v_num=qzkv, train/reward=-7.47, train/loss=-1.81, val/reward=-7.33]
`Trainer.fit` stopped: `max_epochs=2` reached.
Epoch 1: 100%|██████████| 196/196 [00:17<00:00, 11.28it/s, v_num=qzkv, train/reward=-7.47, train/loss=-1.81, val/reward=-7.33]
Testing¶
Plotting¶
Here we plot the solution (greedy rollout) of the trained model to the initial problem
[10]:
# Greedy rollouts over trained model (same states as previous plot)
model = model.to(device)
out = model(td_init.clone(), phase="test", decode_type="greedy", return_actions=True)
# Plotting
print(f"Tour lengths: {[f'{-r.item():.2f}' for r in out['reward']]}")
for td, actions in zip(td_init, out['actions'].cpu()):
env.render(td, actions)
Tour lengths: ['6.96', '8.66', '7.93']
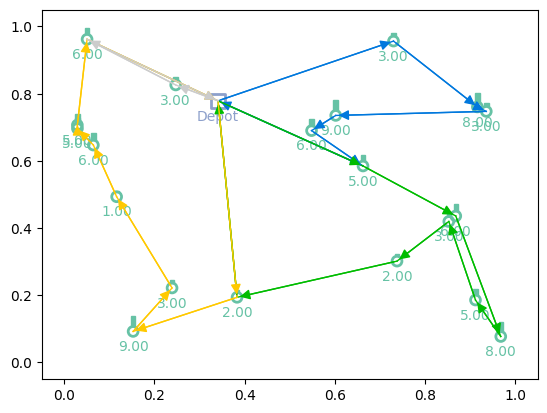
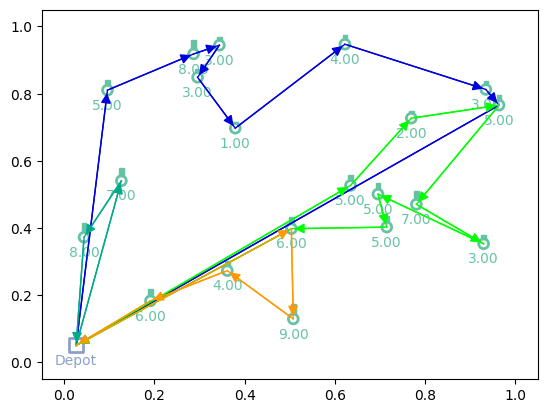
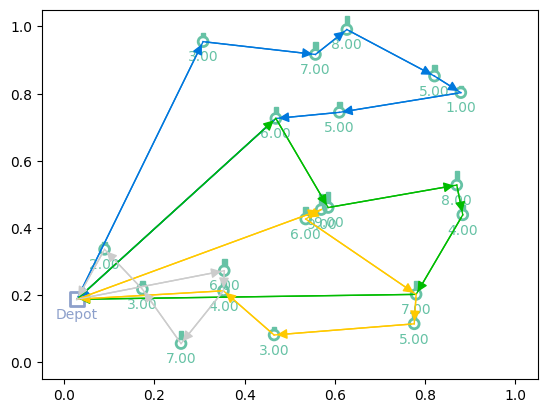
Test function¶
By default, the dataset is generated or loaded by the environment. You may load a dataset by setting test_file during the env config:
env = SDVRPEnv(
...
test_file="path/to/test/file"
)
In this case, we test directly on the generated test dataset
[11]:
trainer.test(model)
val_file not set. Generating dataset instead
test_file not set. Generating dataset instead
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
/home/cbhua/miniconda3/envs/rl4co-user/lib/python3.10/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:441: The 'test_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=31` in the `DataLoader` to improve performance.
Testing DataLoader 0: 100%|██████████| 20/20 [00:00<00:00, 47.27it/s]
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ test/reward │ -7.329767227172852 │ └───────────────────────────┴───────────────────────────┘
[11]:
[{'test/reward': -7.329767227172852}]
Test generalization to new dataset¶
Here we can load a new dataset (with 50 nodes) and test the trained model on it
[12]:
# Test generalization to 50 nodes (not going to be great due to few epochs, but hey)
env = SDVRPEnv(num_loc=50)
# Generate data (100) and set as test dataset
new_dataset = env.dataset(50)
dataloader = model._dataloader(new_dataset, batch_size=100)
Plotting generalization¶
[13]:
# Greedy rollouts over trained model (same states as previous plot, with 20 nodes)
model = model.to(device)
init_states = next(iter(dataloader))[:3]
td_init_generalization = env.reset(init_states).to(device)
out = model(td_init_generalization.clone(), phase="test", decode_type="greedy", return_actions=True)
# Plotting
print(f"Tour lengths: {[f'{-r.item():.2f}' for r in out['reward']]}")
for td, actions in zip(td_init_generalization, out['actions'].cpu()):
env.render(td, actions)
Tour lengths: ['11.94', '14.16', '15.02']
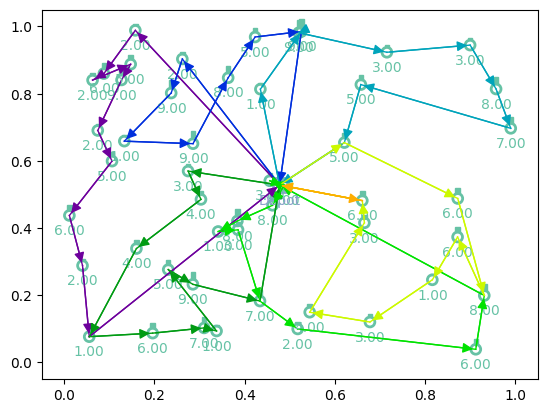
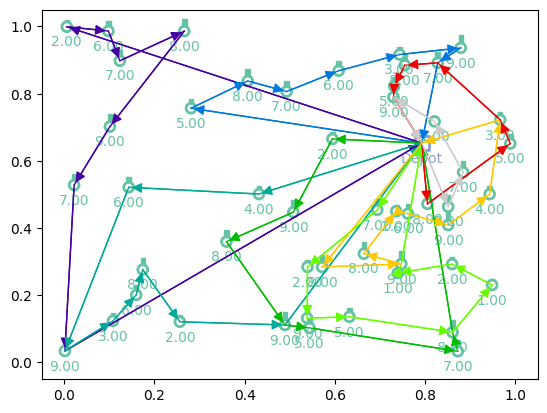
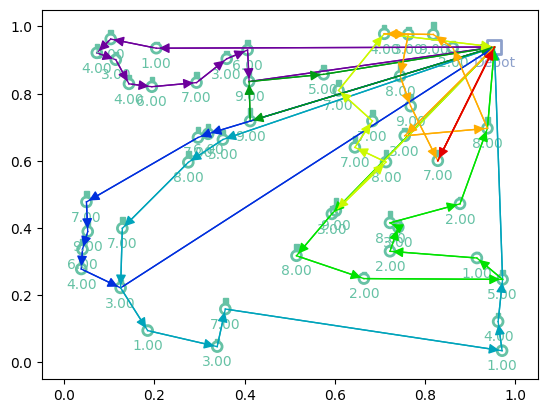
Loading model¶
Thanks to PyTorch Lightning,we can easily save and load a model to and from a checkpoint! This is declared in the Trainer using the model checkpoint callback. For example, we can load the last model via the last.ckpt file located in the folder we specified in the Trainer.
Checkpointing¶
[14]:
# Environment, Model, and Lightning Module (reinstantiate from scratch)
model = AttentionModel(env,
baseline="rollout",
train_data_size=100_000,
test_data_size=10_000,
optimizer_kwargs={'lr': 1e-4}
)
# Note that by default, Lightning will call checkpoints from newer runs with "-v{version}" suffix
# unless you specify the checkpoint path explicitly
new_model_checkpoint = AttentionModel.load_from_checkpoint("checkpoints/last.ckpt", strict=False)
/home/cbhua/miniconda3/envs/rl4co-user/lib/python3.10/site-packages/lightning/pytorch/utilities/parsing.py:198: Attribute 'env' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['env'])`.
/home/cbhua/miniconda3/envs/rl4co-user/lib/python3.10/site-packages/lightning/pytorch/utilities/parsing.py:198: Attribute 'policy' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['policy'])`.
/home/cbhua/miniconda3/envs/rl4co-user/lib/python3.10/site-packages/lightning/pytorch/core/saving.py:177: Found keys that are not in the model state dict but in the checkpoint: ['baseline.baseline.model.encoder.init_embedding.init_embed.weight', 'baseline.baseline.model.encoder.init_embedding.init_embed.bias', 'baseline.baseline.model.encoder.init_embedding.init_embed_depot.weight', 'baseline.baseline.model.encoder.init_embedding.init_embed_depot.bias', 'baseline.baseline.model.encoder.net.layers.0.0.module.Wqkv.weight', 'baseline.baseline.model.encoder.net.layers.0.0.module.Wqkv.bias', 'baseline.baseline.model.encoder.net.layers.0.0.module.out_proj.weight', 'baseline.baseline.model.encoder.net.layers.0.0.module.out_proj.bias', 'baseline.baseline.model.encoder.net.layers.0.1.normalizer.weight', 'baseline.baseline.model.encoder.net.layers.0.1.normalizer.bias', 'baseline.baseline.model.encoder.net.layers.0.1.normalizer.running_mean', 'baseline.baseline.model.encoder.net.layers.0.1.normalizer.running_var', 'baseline.baseline.model.encoder.net.layers.0.1.normalizer.num_batches_tracked', 'baseline.baseline.model.encoder.net.layers.0.2.module.0.weight', 'baseline.baseline.model.encoder.net.layers.0.2.module.0.bias', 'baseline.baseline.model.encoder.net.layers.0.2.module.2.weight', 'baseline.baseline.model.encoder.net.layers.0.2.module.2.bias', 'baseline.baseline.model.encoder.net.layers.0.3.normalizer.weight', 'baseline.baseline.model.encoder.net.layers.0.3.normalizer.bias', 'baseline.baseline.model.encoder.net.layers.0.3.normalizer.running_mean', 'baseline.baseline.model.encoder.net.layers.0.3.normalizer.running_var', 'baseline.baseline.model.encoder.net.layers.0.3.normalizer.num_batches_tracked', 'baseline.baseline.model.encoder.net.layers.1.0.module.Wqkv.weight', 'baseline.baseline.model.encoder.net.layers.1.0.module.Wqkv.bias', 'baseline.baseline.model.encoder.net.layers.1.0.module.out_proj.weight', 'baseline.baseline.model.encoder.net.layers.1.0.module.out_proj.bias', 'baseline.baseline.model.encoder.net.layers.1.1.normalizer.weight', 'baseline.baseline.model.encoder.net.layers.1.1.normalizer.bias', 'baseline.baseline.model.encoder.net.layers.1.1.normalizer.running_mean', 'baseline.baseline.model.encoder.net.layers.1.1.normalizer.running_var', 'baseline.baseline.model.encoder.net.layers.1.1.normalizer.num_batches_tracked', 'baseline.baseline.model.encoder.net.layers.1.2.module.0.weight', 'baseline.baseline.model.encoder.net.layers.1.2.module.0.bias', 'baseline.baseline.model.encoder.net.layers.1.2.module.2.weight', 'baseline.baseline.model.encoder.net.layers.1.2.module.2.bias', 'baseline.baseline.model.encoder.net.layers.1.3.normalizer.weight', 'baseline.baseline.model.encoder.net.layers.1.3.normalizer.bias', 'baseline.baseline.model.encoder.net.layers.1.3.normalizer.running_mean', 'baseline.baseline.model.encoder.net.layers.1.3.normalizer.running_var', 'baseline.baseline.model.encoder.net.layers.1.3.normalizer.num_batches_tracked', 'baseline.baseline.model.encoder.net.layers.2.0.module.Wqkv.weight', 'baseline.baseline.model.encoder.net.layers.2.0.module.Wqkv.bias', 'baseline.baseline.model.encoder.net.layers.2.0.module.out_proj.weight', 'baseline.baseline.model.encoder.net.layers.2.0.module.out_proj.bias', 'baseline.baseline.model.encoder.net.layers.2.1.normalizer.weight', 'baseline.baseline.model.encoder.net.layers.2.1.normalizer.bias', 'baseline.baseline.model.encoder.net.layers.2.1.normalizer.running_mean', 'baseline.baseline.model.encoder.net.layers.2.1.normalizer.running_var', 'baseline.baseline.model.encoder.net.layers.2.1.normalizer.num_batches_tracked', 'baseline.baseline.model.encoder.net.layers.2.2.module.0.weight', 'baseline.baseline.model.encoder.net.layers.2.2.module.0.bias', 'baseline.baseline.model.encoder.net.layers.2.2.module.2.weight', 'baseline.baseline.model.encoder.net.layers.2.2.module.2.bias', 'baseline.baseline.model.encoder.net.layers.2.3.normalizer.weight', 'baseline.baseline.model.encoder.net.layers.2.3.normalizer.bias', 'baseline.baseline.model.encoder.net.layers.2.3.normalizer.running_mean', 'baseline.baseline.model.encoder.net.layers.2.3.normalizer.running_var', 'baseline.baseline.model.encoder.net.layers.2.3.normalizer.num_batches_tracked', 'baseline.baseline.model.decoder.context_embedding.project_context.weight', 'baseline.baseline.model.decoder.dynamic_embedding.projection.weight', 'baseline.baseline.model.decoder.project_node_embeddings.weight', 'baseline.baseline.model.decoder.project_fixed_context.weight', 'baseline.baseline.model.decoder.logit_attention.project_out.weight']
val_file not set. Generating dataset instead
test_file not set. Generating dataset instead
Now we can load both the model and environment from the checkpoint!
[15]:
# Greedy rollouts over trained model (same states as previous plot, with 20 nodes)
model = new_model_checkpoint.to(device)
env = new_model_checkpoint.env.to(device)
out = model(td_init.clone(), phase="test", decode_type="greedy", return_actions=True)
# Plotting
print(f"Tour lengths: {[f'{-r.item():.2f}' for r in out['reward']]}")
for td, actions in zip(td_init, out['actions'].cpu()):
env.render(td, actions)
Tour lengths: ['6.96', '8.66', '7.93']
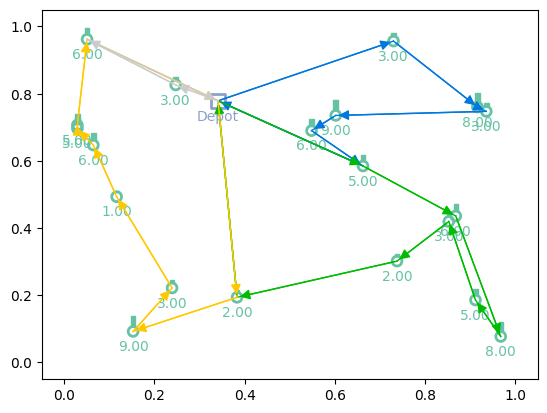
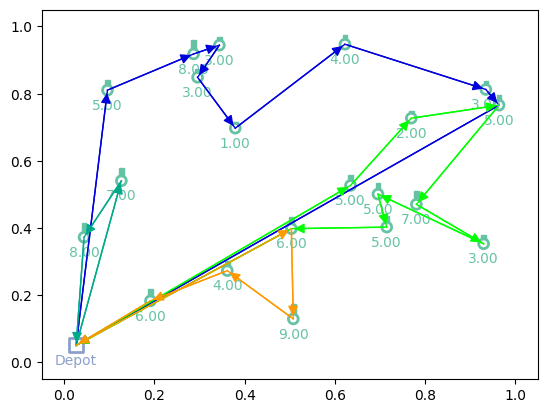
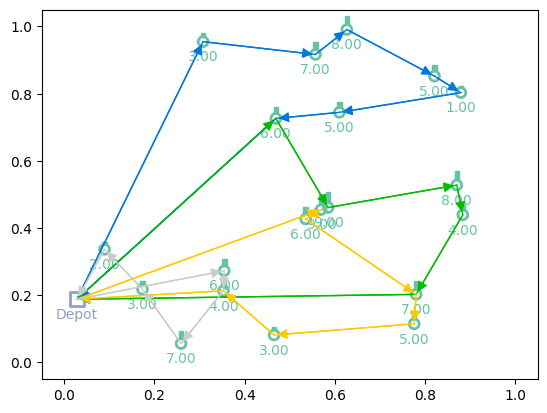
Additional resources¶
Documentation | Getting Started | Usage | Contributing | Paper | Citation
Have feedback about this notebook? Feel free to contribute by either opening an issue or a pull request! ;)
