RL4CO Quickstart Notebook¶
![]()
Documentation | Getting Started | Usage | Contributing | Paper | Citation
In this notebooks we will train the AttentionModel (AM) on the TSP environment for 20 nodes. On a GPU, this should less than 2 minutes! 🚀

Installation¶
[1]:
## Uncomment the following line to install the package from PyPI
## You may need to restart the runtime in Colab after this
## Remember to choose a GPU runtime for faster training!
# !pip install rl4co
Imports¶
[2]:
import torch
from rl4co.envs import TSPEnv
from rl4co.models.zoo import AttentionModel, AttentionModelPolicy
from rl4co.utils.trainer import RL4COTrainer
/home/botu/mambaforge/envs/rl4co-new/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Environment, Policy and Model¶
Full documentation of:
[3]:
# RL4CO env based on TorchRL
env = TSPEnv(num_loc=50)
# Policy: neural network, in this case with encoder-decoder architecture
policy = AttentionModelPolicy(env.name,
embedding_dim=128,
num_encoder_layers=3,
num_heads=8,
)
# Model: default is AM with REINFORCE and greedy rollout baseline
model = AttentionModel(env,
baseline="rollout",
train_data_size=100_000,
val_data_size=10_000,
optimizer_kwargs={"lr": 1e-4},
)
/home/botu/mambaforge/envs/rl4co-new/lib/python3.11/site-packages/lightning/pytorch/utilities/parsing.py:198: Attribute 'env' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['env'])`.
/home/botu/mambaforge/envs/rl4co-new/lib/python3.11/site-packages/lightning/pytorch/utilities/parsing.py:198: Attribute 'policy' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['policy'])`.
Test greedy rollout with untrained model and plot¶
[4]:
# Greedy rollouts over untrained model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
td_init = env.reset(batch_size=[3]).to(device)
model = model.to(device)
out = model(td_init.clone(), phase="test", decode_type="greedy", return_actions=True)
actions_untrained = out['actions'].cpu().detach()
rewards_untrained = out['reward'].cpu().detach()
for i in range(3):
print(f"Problem {i+1} | Cost: {-rewards_untrained[i]:.3f}")
env.render(td_init[i], actions_untrained[i])
Problem 1 | Cost: 14.890
Problem 2 | Cost: 26.188
Problem 3 | Cost: 16.098
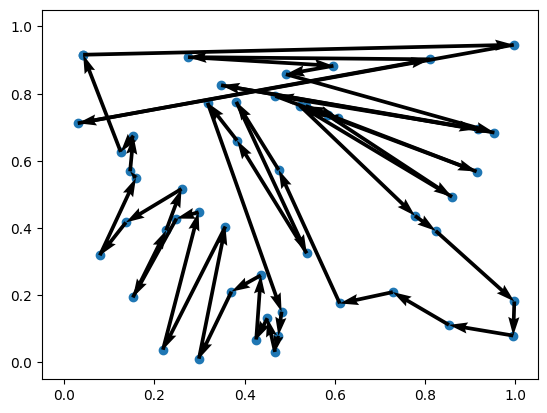
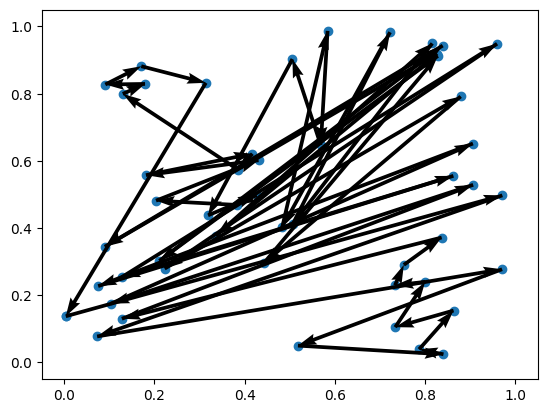
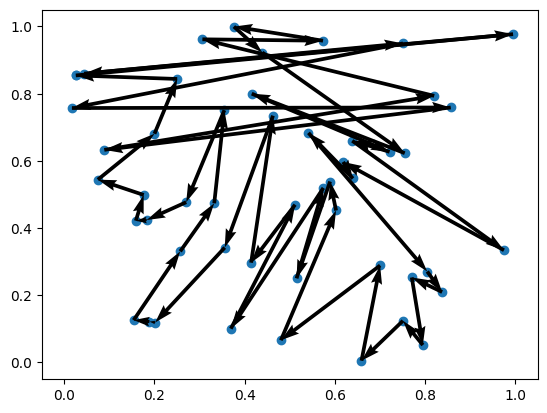
Trainer¶
The RL4CO trainer is a wrapper around PyTorch Lightning’s Trainer class which adds some functionality and more efficient defaults
[5]:
trainer = RL4COTrainer(
max_epochs=3,
accelerator="gpu",
devices=1,
logger=None,
)
Using 16bit Automatic Mixed Precision (AMP)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
/home/botu/mambaforge/envs/rl4co-new/lib/python3.11/site-packages/lightning/pytorch/trainer/connectors/logger_connector/logger_connector.py:67: Starting from v1.9.0, `tensorboardX` has been removed as a dependency of the `lightning.pytorch` package, due to potential conflicts with other packages in the ML ecosystem. For this reason, `logger=True` will use `CSVLogger` as the default logger, unless the `tensorboard` or `tensorboardX` packages are found. Please `pip install lightning[extra]` or one of them to enable TensorBoard support by default
Fit the model¶
[6]:
trainer.fit(model)
val_file not set. Generating dataset instead
test_file not set. Generating dataset instead
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
| Name | Type | Params
--------------------------------------------------
0 | env | TSPEnv | 0
1 | policy | AttentionModelPolicy | 710 K
2 | baseline | WarmupBaseline | 710 K
--------------------------------------------------
1.4 M Trainable params
0 Non-trainable params
1.4 M Total params
5.681 Total estimated model params size (MB)
/home/botu/mambaforge/envs/rl4co-new/lib/python3.11/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:441: The 'val_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=31` in the `DataLoader` to improve performance.
/home/botu/mambaforge/envs/rl4co-new/lib/python3.11/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:441: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=31` in the `DataLoader` to improve performance.
Epoch 2: 100%|██████████| 196/196 [00:11<00:00, 17.24it/s, v_num=67, train/reward=-6.69, train/loss=-2.89, val/reward=-6.40]
`Trainer.fit` stopped: `max_epochs=3` reached.
Epoch 2: 100%|██████████| 196/196 [00:13<00:00, 14.70it/s, v_num=67, train/reward=-6.69, train/loss=-2.89, val/reward=-6.40]
Testing¶
[7]:
# Greedy rollouts over trained model (same states as previous plot)
model = model.to(device)
out = model(td_init.clone(), phase="test", decode_type="greedy", return_actions=True)
actions_trained = out['actions'].cpu().detach()
# Plotting
import matplotlib.pyplot as plt
for i, td in enumerate(td_init):
fig, axs = plt.subplots(1,2, figsize=(11,5))
env.render(td, actions_untrained[i], ax=axs[0])
env.render(td, actions_trained[i], ax=axs[1])
axs[0].set_title(f"Untrained | Cost = {-rewards_untrained[i].item():.3f}")
axs[1].set_title(r"Trained $\pi_\theta$" + f"| Cost = {-out['reward'][i].item():.3f}")
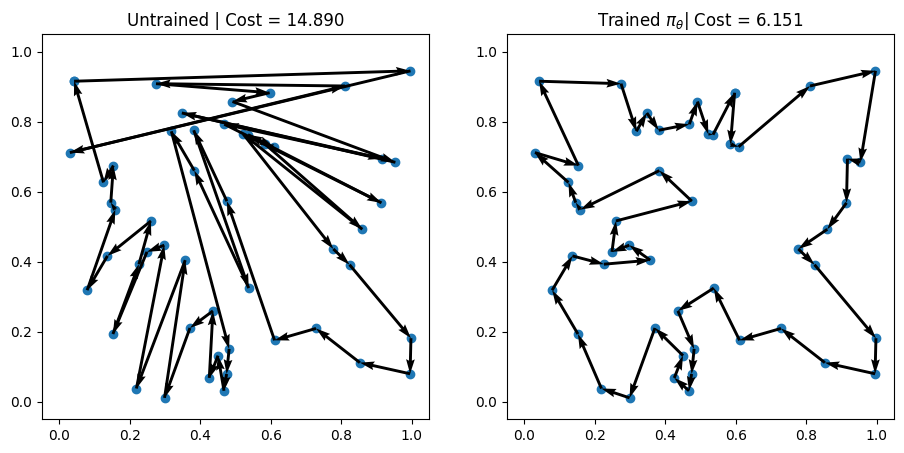
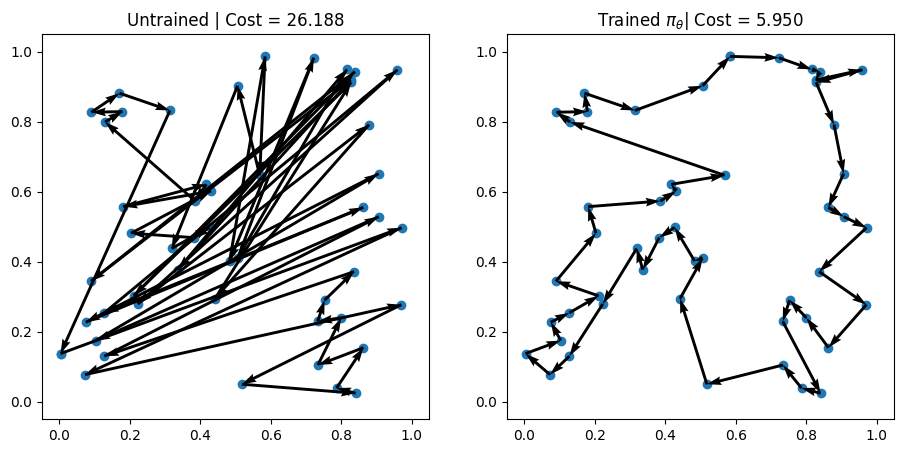
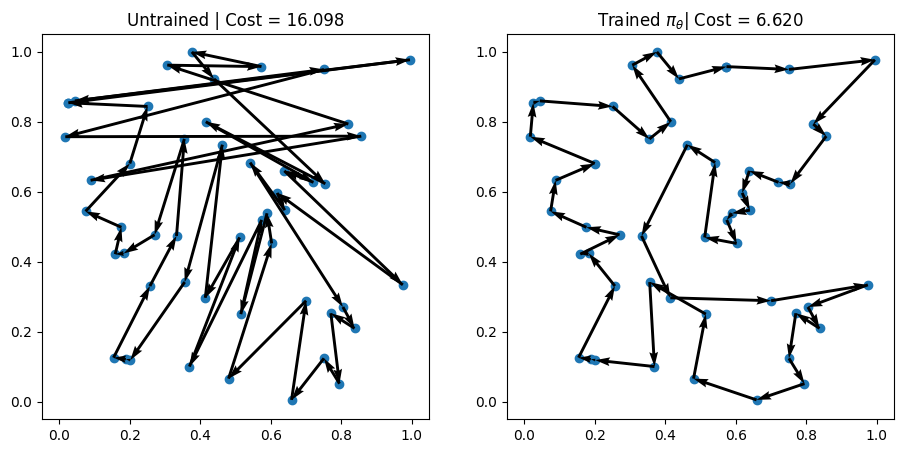
We can see that even after just 3 epochs, our trained AM is able to find much better solutions than the random policy! 🎉
[8]:
# Optionally, save the checkpoint for later use (e.g. in tutorials/4-search-methods.ipynb)
trainer.save_checkpoint("tsp-quickstart.ckpt")
